실험환경

주요변경옵션

leveldb 부분 구조 (memtable부분)

write_buffer_size = memtable 하나의 최대 크기 default = 4M
max_file_size = memtable 안에 들어가 있는 sst파일의 최대 크기 default = 2M
(memtable중 max_file_size의 크기는 write_buffer_size보다 크게 성정할수 있지만 실제 memtable중에서는 sst의 size는 write_buffer_size로서 제한이 됩니다) (max_file_size는 memtable에 들어가 있는 sst 의 size만 아니라 disk level에 들어가 있는 sst의 size도 같이 지정합니다)
fillseq & fillrandom
sync; echo 3 > /proc/sys/vm/drop_caches
for j in {2097152,4194304,8388608,16777216,33554432}
do
for i in {2097152,4194304,8388608,16777216,33554432}
do
echo "write_buffer_size is $j" | tee -a result.txt
CMD="./db_bench --benchmarks="fillseq,stats" --use_existing_db=0 --num=1000000 --write_buffer_size=$j --max_file_size=$i"
CMD="./db_bench --benchmarks="fillrandom,stats" --use_existing_db=0 --num=1000000 --write_buffer_size=$j --max_file_size=$i"
RESULT=$($CMD)
echo "$RESULT" | tee -a result.txt
echo | tee -a result.txt
done
done
결과:

1. fillseq의benchmark결과에서 규칙성을 발견하지 못하지만 fillrandom과 비교하면 전체적으로 latency가 좋으걸로 보입니다
2. fillrandom의 결과에서 대략으로 write_buffer_size와 max_file_size를 크게하면 latency가 좋아지는걸로 보입니다
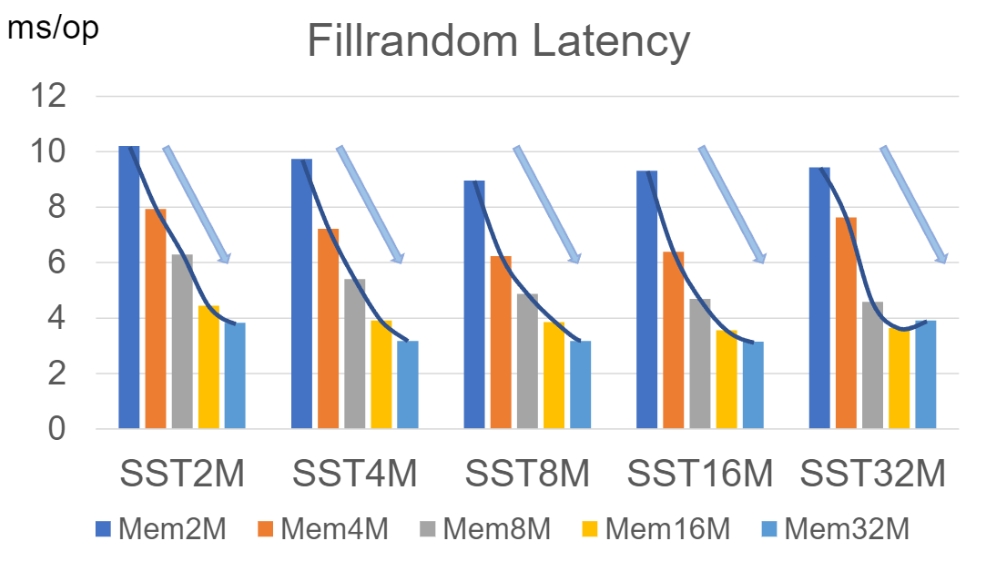
분석:
1. fillseq은 kv pair들을 key기준으로 작은key부터 순차적으로 memtable에 들어가 immutable로 변환후 disk level로 내려갑니다. 이 과정에서는 merge sorting 이 필요없고 각 sst의 key range가 절때 중첩하지 않아 compaction의 속도가 빠릅니다. fillrandom은 key가 rand함수로 가져오기 때문에 순서가 없이 memtable에들어가서 skiplist로서 정열이 되지만 memtable등 포함한 상위 레벨에 있는 sst의 key range가 겹칠수 밖에 없습니다 , 이로서 compaction 소모시간도 길어집니다.
2. 

level0에서 compaction이 발생하는 조건이 sst파일이 4개 되는 것입니다. 즉 level0의 크기는 dump해서 내려온 immutable자체의 크기 * 4, write_buffer_size * 4 로 보면 됩니다.
write_buffer_size가 크지면 level 0 에 있는 sst가 크지고 compaction이 진행할때 한번의 처리량이 올라가서 write성능이 좋아집니다.
write_buffer_size는 memtable의 크기와 level 0 중 sst의 크기를 정하고 max_file_size는 level 1 부터 모든 하위 level의 sst크기를 정해서 크면 크질수록 sst의 개수를 주리는 방식으로 compaction의 빈도를 주릴수 있고 write성능을 향상 시킵니다. (주의: sst size가 크면 클수록 compaction의 read/write amplification이 커집니다.)
readrandom
fillseq & fillradnom으로 db를 load후 readrandom의 결과입니다
